Clanker DevOps
For teams that need infrastructure context, deploy planning, incident investigation, cost review, security checks, and reviewed changes across providers.
Clanker Cloud is the workspace where a team can ask a Clanker to understand the systems it works in, use the right tools, and hand back work that is ready to review.
Use Clanker DevOps for infrastructure and operations, Clanker Workspace patterns for PM and office work, and Clanker Secretary when the job needs a real computer operated from anywhere.
The workspace is not a chat box on the side. It is where the Clanker gets context, uses tools, asks for approval, and keeps the work moving.
For teams that need infrastructure context, deploy planning, incident investigation, cost review, security checks, and reviewed changes across providers.
For PMs and operators who need research, spreadsheets, follow-ups, reporting, ticket updates, account checks, and weekly business workflows completed cleanly.
For work that cannot be solved through an API alone: logging into tools, navigating screens, reading documents, filling forms, checking portals, and handing back finished work.
Cloud credentials, local tools, and model keys stay in the boundary the user chooses while Clanker Cloud coordinates the work.
A Clanker should read the current systems, files, apps, repos, or workflow state before it writes a plan or takes action.
Deploys, sends, account changes, deletes, purchases, and publishes stay behind approval instead of being hidden inside a chat answer.
The same account can start with the desktop app, downloads, MCP setup, Clanker Secretary, or hosted sandboxes depending on the workflow.
The workspace keeps the work visible. A Clanker can inspect context, draft a plan, create a focused agent, and leave a reviewable trail instead of scattering the job across chat, tickets, and consoles.
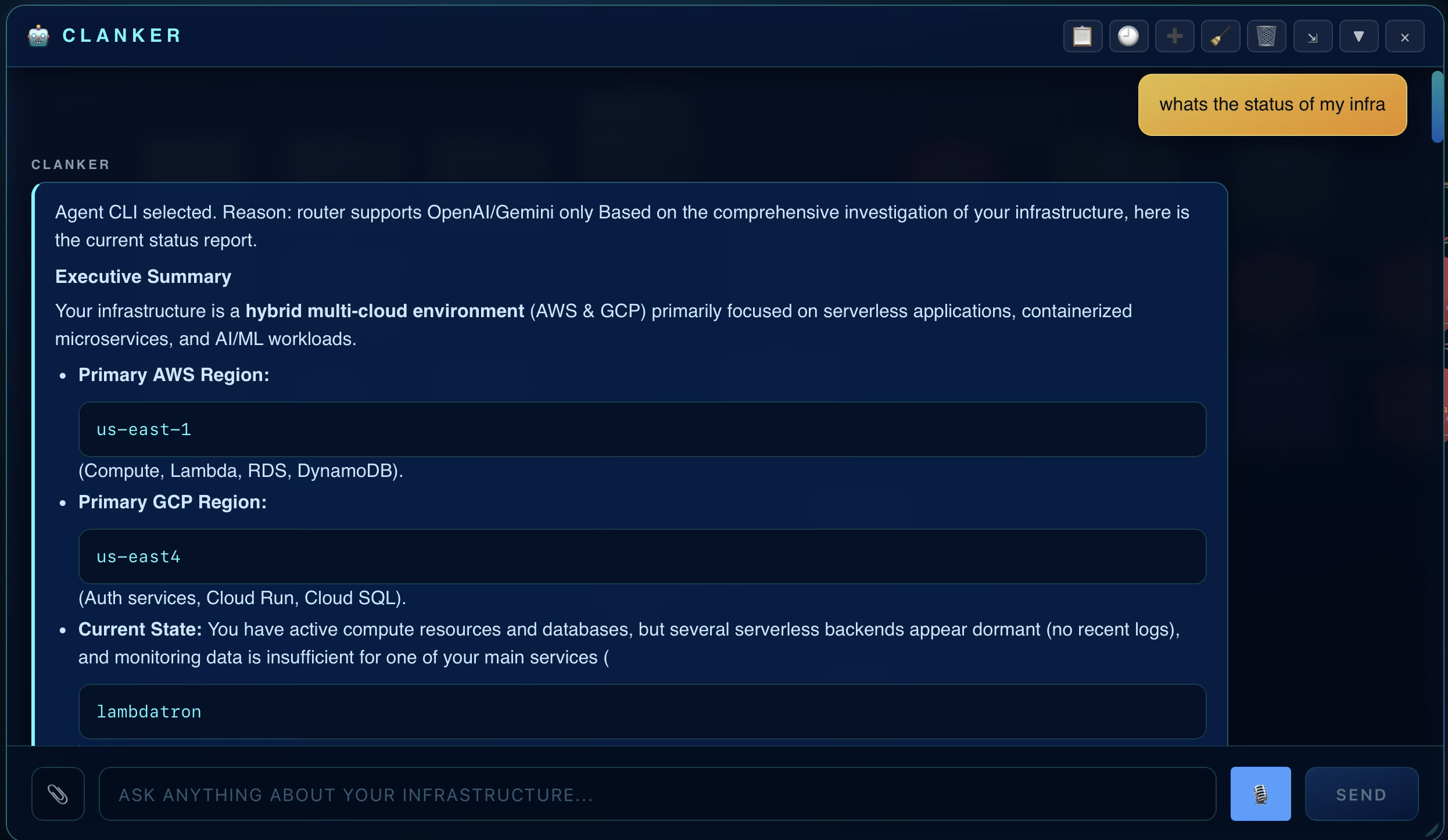
Start from the outcome or problem. The workspace keeps the relevant context close to the answer.
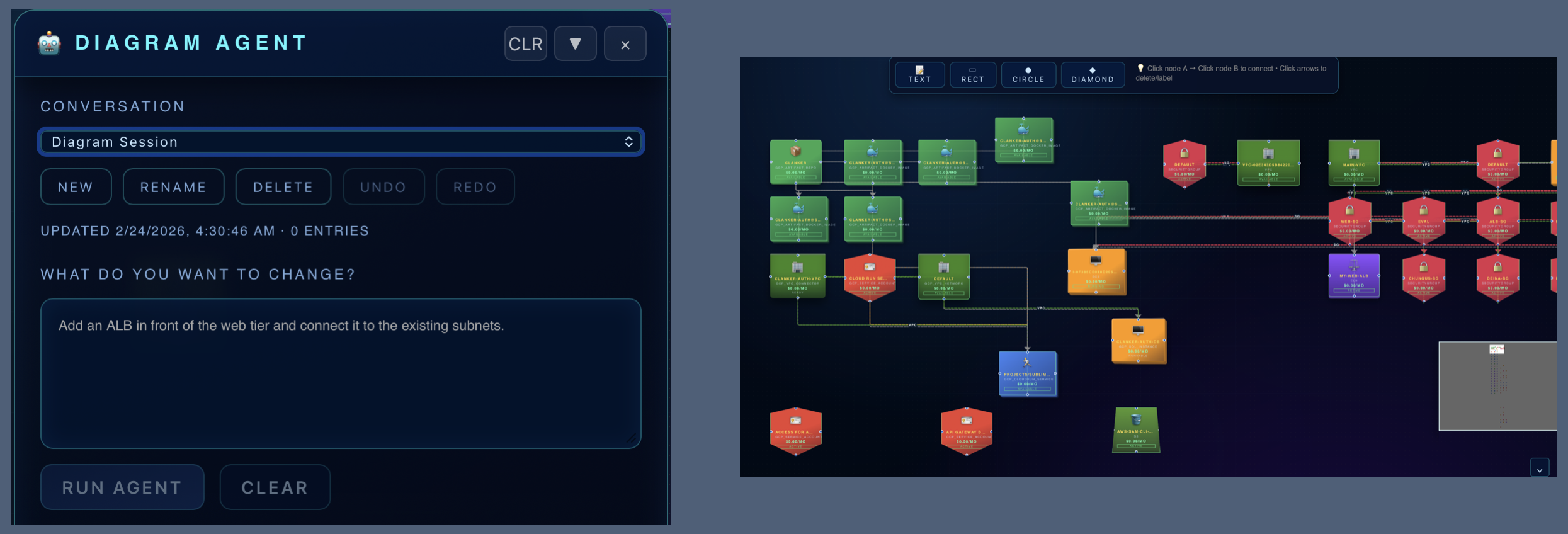
Use plans for the parts of a job that need evidence, approval, and a clean handoff.
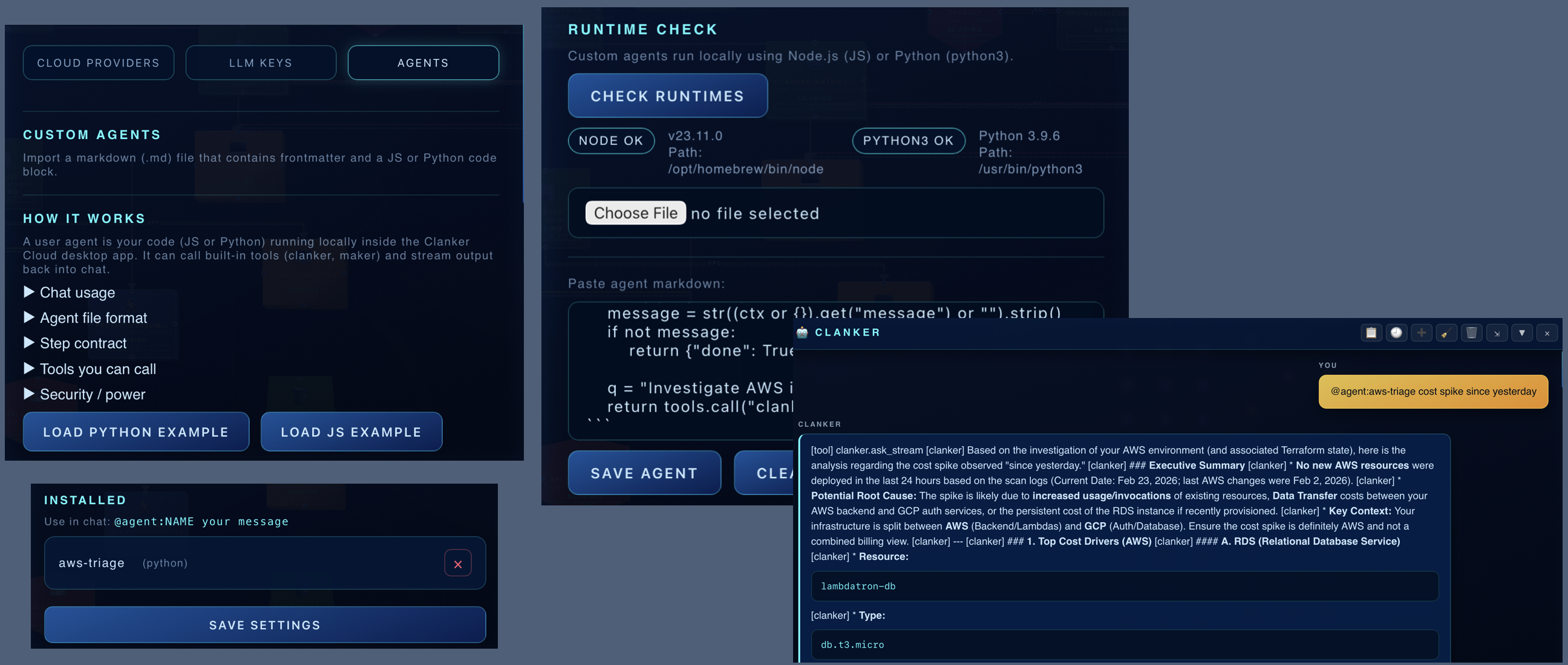
When a workflow repeats, package the context and rules so it can run again without starting over.
The goal is not another inbox. It is a place where humans and agents can see the same context, agree on the next step, and keep the result attached to the work.
Operate across cloud, Kubernetes, GitHub, deploys, cost, security, and incidents from one provider-agnostic workspace.
Track follow-ups, summarize evidence, update sheets, prepare reports, and keep recurring business work from getting stuck between tools.
Clanker Secretary can use browsers, desktop apps, files, SaaS tools, and internal systems on a worker computer.
Hosted sandboxes give agents a clean place to run commands, hold state, publish outputs, and ask for approval.
Use these walkthroughs to see how Clanker Cloud keeps context, findings, approvals, and agent handoffs visible across the main workspace and a phone-sized review surface.
A Clanker Cloud walkthrough showing context, findings, and reviewed follow-up work.
A phone-sized view of agent-managed Clanker Cloud work, with the same workspace and approval model behind it.
Start with the finished result you need, not a list of buttons. Name the systems, deadline, and approval rules.
The workspace pulls together cloud state, repo context, app screens, files, browser pages, or business records depending on the job.
Changes, sends, deletes, purchases, publishes, and account actions should pass through approval before they happen.
When the same workflow keeps coming back, host it as a durable automation on Clanker Cloud or in a private enterprise deployment.
Provider-agnostic DevOps workspace for incidents, deploys, cost, security, and operations.
Workflow automation for reports, follow-ups, spreadsheets, portals, and repeatable office tasks.
Full computer control from anywhere for work across browsers, apps, files, and internal systems.
No. Workspace is the way Clanker Cloud is organized for different kinds of work: DevOps, PM and office workflows, full computer control, and hosted agent runs.
Use Clanker Secretary when the workflow depends on a real UI, browser session, desktop app, file, or internal system that does not have a clean API path.
Pick the DevOps, automation, or computer-control path and keep the same Clanker Cloud account and approval model around the work.